Um Daten längerfristig zu speichern und sie gleichzeitig auch einfach zugänglich zu machen, nutzt man Datenbanken. Grundsätzlich kann man sich Datenbanken wie Tabellen vorstellen.
Begriffe
 Quelle: moodle
Quelle: moodle
Tabellenname
Der Tabellenname gibt den Sinn der Datenbank an. Meist beschreibt er den Inhalt.
Schema
Ein Schema legt fest, welche Daten in einer Tabellle enthalten sind.
Eine andere Schreibweise für ein Schema sieht wie folgt aus: Buch(ISBN, Titel, Autor, Preis). Im späteren Verlauf dieses Artikels wird diese Schreibweise noch erweitert.
Attribut
Jedes Schema beschreibt die verschiedenen Attribute. Ein Attribut hat dabei immer einen festgelegten Datentyp. Außerdem gibt es immer ein oder mehrere Schlüsselattribute, durch die jede Zeile (Datensatz) angesprochen werden kann. Diese Schlüsselattribute müssen einzigartig sein.
Redundanzen
Redundanzen tretten bei gleichen Datensätzen in einer Datenbank auf. In dem obigen Beispiel Buch könnte beispielsweise Herr der Ringe als Redundant betrachtet werden, da es sich um den gleichen Autor und den gleichen Titel handelt. Dennoch handelt es sich um unterschiedliche ISBNs und die beiden Einträge haben unterschiedliche Preise.
Anomalien
Sollten sich die ISBNs der beiden Herr der Ringe Bücher nicht unterscheiden, so wären die Datensätze widersprüchlich zu einander, da es gleiche Bücher mit unterschiedlichen Preisen geben würde.
Beispiel
Wir schauen uns die Firma Schule24 Gmbh an. Da sie eine sehr soziale Firma ist, die auf das Wohl der Mitarbeiter achtet, können bestimmte Ausgaben erstattet werden. Allerdings müssen diese Ausgaben im Sinne des Unternehmens getätigt werden. Möglich als Erstattung ist zum Beispiel das Mittagessen, aber auch Bücher für das Lernen, etc. Eine Person aus der Finanzverwaltung kümmert sich dann darum, dass auch die jeweiligen Ausgaben erstattet werden.

Die Möglichkeit Bezahlt ist ein Wahrheitswert, der angibt, ob das Geld dem Mitarbeiter schon erstattet worden ist.

Als Attribut dient der Username. Aus diesem Grund muss auch jeder Nutzername einzigartig sein. Würde in der Firma zwei Mitarbeiter mit dem gleichen Name arbeiten, kann eine Anomalie entstehen. Für den Zweck des Beispieles reicht die aktuelle Modellierung jedoch aus.

In der Erstattungs-Datenbank werden sowohl Username als auch Ausgaben-ID als Schlüsselattribut gewertet. Da jede Ausgabe auch nur einmal bezahlt werden kann, ist die vorhandene Kombination einzigartig.
Eins ist zu wenig
Generell ist es eine sinnvolle Idee, dass man nicht nur eine Tabelle hat, sondern mehrere unterschiedliche Tabellen, die sich aufeinander beziehen. Der Vorteil ist zum einen die Übersichtlichkeit und die geringere Fehleranfälligkeit, aber auch die Veringerung von Schreibaktionen, die für Veränderungen notwendig sind.
Malen nach Zahlen - Entity Relation Modell
Die Modellierung einer Datenbank kann in einem Entity-Relation Modell gezeigt werden. Dabei handelt es sich um eine grafische Darstellung der Datenbank.
Begriffe

Entität
Eine Entität ist ein Objekt aus der Realsituation, über das Informationen zu speichern sind. –Moodle
Jede Tabelle aus dem obigen Beispiel wäre demnach eine Entität.
Beziehung
Eine Beziehung beschreibt den Zusammenhang von Entitäten untereinander. –Moodle
Unterschiedliche Datenbanken müssen miteinander verknüpft werden. Das kann zum beispiel - wie im obigen Beispiel - der Nutzername eines Benutzers sein, der in der aktuellen Datenbank Veränderungen vorgenommen hat. Durch den einzigartigen Nutzernamen kann dann mehr Information zu diesem Benutzer eingeholt werden.
Attribut
Ein Attribut bezeichnet die Eigentschaft einer Entität oder einer Beziehung.
Ein Schlüssselattribut beschreibt zusätzlich die Einzigartigkeit dieses Attributes.
Beispiel
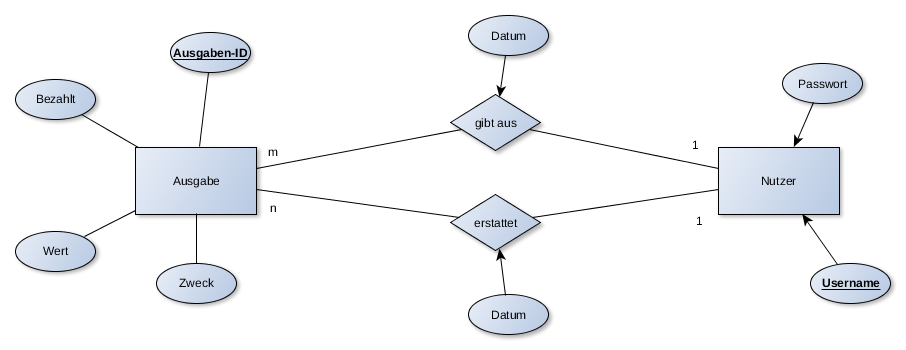
Der obige Graph stellt das Entity-Relation Modell der Ausgaben-Modellierung dar.
Kardinalitäten
Um anzugeben, wie viele Entitäten an an einer Beziehung beteiligt sind, benutzt man Kardinalitäten. Im obigen ER-Modell sind sie als Angaben an den ausgehenden Verbindungen der Entitäten zu erkennen. Sie geben beispielsweise an, dass ein Nutzer m Ausgaben ausgeben kann und n Ausgaben von einer Person erstattet werden können.
Kardinalitäten können folgende Formen annehmen:
- 1:1
- n:m
- n:1
erweiterte schematische Schreibweise
Um die Relationen auch in der schmatischen Schreibweise darzustellen gibt es unterschiedliche Möglichkeiten, die abhängig sind von der Kardinalität.
- bei einer 1:1 Beziehung lassen sich beide Entitäten in ein Schema fassen.
- bei einer 1:n Beziehung benutzt man zwei Schematas, die durch Schlüsselattribute ihre Beziehung darstellen.
- bei einer n:m Beziehung benutzt man drei Schematas. Zwei Schematas stellen jeweils die Entität dar, und das letzte stellt die Beziehung dar.
Beispiel

Bei dieser Schreibweise werden die Fremdschlüssel mit einem Pfeil nach oben angegeben. Die Beziehungen der verschiedenen Entitäten wird dadurch sichtbar gemacht.
Datenbanken verbessern durch Normalisierung
Datenbanken müssen nicht immer zwangsläufig neu geschrieben werden, wenn sie nicht mehr übersichtlich oder logisch aufgebaut sind. Bestehende Datenbanken können auch verbessert werden. Diesen Vorgang bezeichnet man als Normalisierung. Im folgenden wird dieses Vorgehen näher erläutert.
Neuerdings hat die Firma Schule24 Gmbh auch eine eigene Kantine. Da aber die Datenbank, um die Essensausgaben zu überwachen, nicht ordentlich geplant wurde, ist vieles unübersichtlich geworden.
Aktuell sieht die Datenbank folgendermaßen aus:
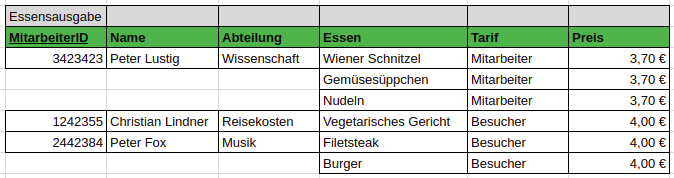
Schrittweise soll nun die Datenbank umgeformt werden, sodass eine übersichtliche Struktur entsteht.
1. Normalform
Wie man erkennen kann, sind in der Datenbank mehrere Datensätze pro Schlüssel verfügbar. Dies soll nun aufgehoben werden.
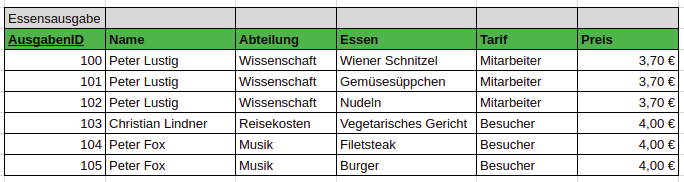
Sicherlich wäre es auch gut, dass man den Name in Vor- und Nachname aufteilt, aus Platzgründen wird dieses Attribut jedoch nicht aufgeteilt.
Definition
Eine Tabelle befindet sich in der ersten Normalform, wenn alle Attribute einen atomaren* wertebereich haben. –Moodle
atomar: Ein Attributswert enhält keine komplexen Wertebelegungen. So teilt man beispielsweise Name in Vor- und Nachname auf. Jeder Wert enthält also nur eine Information.
2. Normalform
Um die Redundanz, die auch zu Anomalien führen kann, zu verringern, sucht man funktionale Abhängigkeiten und lagert alle Attribut mit der selben Abhängigkeit aus. Die zweite Normalform ist nur bei Attributen mit voller funktionaler Abhängigkeit erreicht.
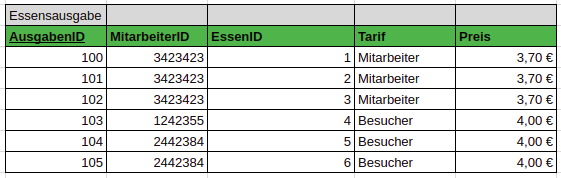
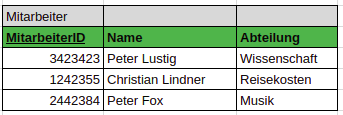
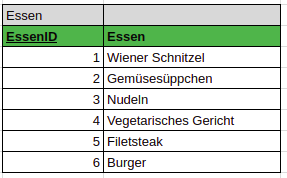
Abhängigkeiten
Ein Attribut B ist von einem Attribut A funktional abängig, wenn durch jeden Wert von A eindeutig ein Wert für B entsteht. –Moodle
Ein Attribut B ist von einer Attributskobination (A1, A2) voll funktional abhängig, wenn B funktional abhängig von der Kombination (A1, A2) ist, nicht aber breits A1 oder A2. –Moodle
Funktionale Abhängigkeiten werden folgendermaßen notiert:
MitarbeiterID -> Name, Abteilung
Definition
Ein Datenbankschema ist in der zweiten Normalform, wenn es in der 1NF ist und zusätzlich jedes Nichtschlüsselattribut vom Primärschlüssek voll funktional abhängig ist und nicht bereits von einem Teil der Schlüsselattribute. –Moodle
3. Normalform
In dem letzten Schritt wird nach transitiven Abhängigkeiten geschaut.
ein Attribut C ist von einem Attribut A transitiv abhängig, wenn es ein Attribut B gibt, mit A -> B -> C. Dabei darf A nicht funktional abhängig von B sein. –Moodle
Das bedutet, dass nach Attributen geschaut wird, die nicht direkt nötig sind und beispielsweise außerhalb definiert sind. In unserem Fall ist das der Tarif
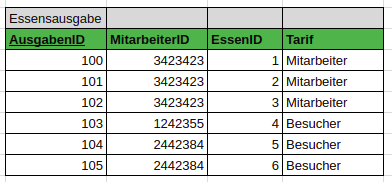
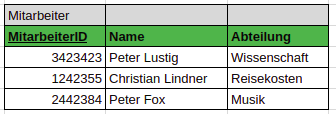
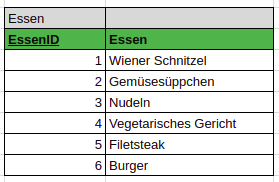
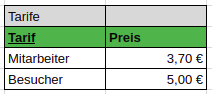
Definition
Ein Datenbanschema ist in der dritten Normalform, wenn es in der 2NF ist und es zusätzlich kein Nichtschlüsselattribut gibt, das transtitiv abhängig von einem Schlüsselattribut ist. Es darf also keine funktionalen Abhängigkeiten zwischen Nichtschlüsselattributen geben. –Moodle
Die Datenbank ist nun übersichtlicher und deutlich leichter zu benutzen.